I want to discuss two papers which deal with unobserved heterogeneity in dynamic discrete choice models, Arcidiacono & Jones (2003) and Arcidiacono & Miller (2011), but first it will help to review the estimation routine that they are based on, the expectation-maximization (EM) algorithm. Kenneth Train provides a comprehensive overview of these methods in his book “Discrete Choice Methods with Simulation” and I would highly recommend reading section 14.2 to get an understanding of why the algorithm works. One of the examples that I use below is based on his paper “A Recursive Estimation for Random Coefficients Model“, the data for which is provided in the mlogit package in R.
The EM algorithm is a quintessential example of how generalizing a problem can sometimes make it simpler. First, consider standard maximum likelihood estimation. We want to find the parameter estimates that maximize the log-likelihood of generating our sample, i.e.

Let 
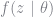
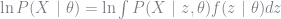
If we had access to the missing data then a reasonable estimation procedure would be to maximize the joint log-likelihood of the sample and the missing data. Of course, the missing data is just that, missing. Because we know 


The joint likelihood is given by

so the conditional expectation is given by

It turns out that the estimator which maximizes this expected log-likelihood will also maximize our original log-likelihood. Furthermore, there is a simple iterative process which is guaranteed to converge to a local maximum of the likelihood function. Instead of maximizing 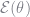


We can then take the parameter estimate 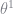
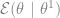
Replicating Train’s Analysis
In this paper, Train is modeling the behavior of agents choosing between four electricity providers. He parameterizes the utility from choice 
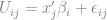
Train’s data is setup in a wide format. The second column gives the agent’s ID and the first column records the agent’s choice in situation 
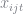
using DataFrames
using DataFramesMeta
electricity = readtable("[path]/Electricity.csv", header = true, separator = ',');
dataMat = convert(Array, electricity)
ids = unique(dataMat[:,2])
He parameterizes the utility from choice
where 

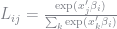
The below function takes a vector of the 

function L(obs_n, choice_n, β_n)
choiceCols = collect(2+choice_n:4:26)
base = obs_n[choiceCols]' * β_n'
denom = zeros(obs_n[choiceCols]' * β_n' )
for j = 1:4
optCols = collect(2+j:4:26)
denom .+= exp( obs_n[optCols]' * β_n' .- base )
end
return 1 ./ denom
end
Each agent is observed in 

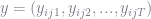
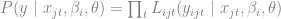
In this case, our missing data 




where

Note that we can calculate 



where 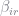





using StatsFuns
R = 200 # Number of sampled draws
function Halton(i = 1, b = 3)
f = 1 # value
r = 0
while i > 0
f = f / b
r = r + f * mod(i, b)
i = floor(i/b)
end
return r
end
function HaltonDraws( k=6, n = 200, primeList = [3, 7, 13, 11, 2, 5])
draws = zeros(n, k)
myPrimes = primeList
for j = 1:k
draws[:,j] = [Halton(i, myPrimes[j]) for i = 100:100+n - 1]';
end
println(myPrimes)
return draws
end
halt = HaltonDraws(6, R * length(ids))
srand(123456)
halt = mod( rand(size(halt)) .+ halt, 1 )
for i = 1:(R * length(ids))
for j = 1:6
halt[i,j] = norminvcdf(halt[i,j] )
end
end
We start with an initial guess for the parameter estimates. I start with
b0 = [1.0 1.0 1.0 1.0 1.0 1.0] W0 = eye(6)*10 + 5 c = chol(W0) βs = [] ws = []
where b0 is the vector of means and W0 the covariance matrix for our normal distribution, and c is the Cholesky decomposition of W0. We can now create a sequence of draws for
βnr = b0 .+ halt[200*(i-1)+1:200*i, :] * c
Our simulated likelihood for agent 
tmpInd = find(dataMat[:,2] .== i)
obs = dataMat[ tmpInd ,:]
βnr = b0 .+ halt[R*(i-1)+1:R*i, :] * c
wnr = ones(R)
for t = 1:size(obs,1)-1
sub = obs[t,:]
Ls = L(sub, sub[1], βnr)
wnr = wnr .* Ls'
end
P_y = mean(wnr)
(the astute reader will notice that we calculate the likelihood with 
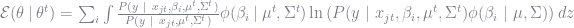
(where we have now summed over the 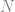
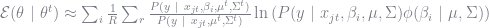
Note that 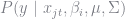


This maximization problem is simple to carry out, it is just the maximum likelihood estimator for a weighted normal distribution, i.e. the weighted mean and weighted covariance. Therefore

and
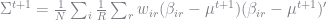
where

My combined code for the EM algorithm is
@time while criter > .001
c = chol(W0)
βs = []
ws = []
for i = 1:length(ids)
tmpInd = find(dataMat[:,2] .== i)
obs = dataMat[ tmpInd ,:]
βnr = b0 .+ halt[R*(i-1)+1:R*i, :] * c
wnr = ones(R,1)
for j = 1:size(obs,1)-1
sub = obs[j,:]
Ls = L(sub, sub[1], βnr)
wnr = wnr .* Ls'
end
append!(βs, [βnr])
append!(ws, wnr ./ mean(wnr) )
end
βs = vcat(βs...)
b1 = sum(ws .* βs, 1) / (length(ids) * R)
weightedW = zeros(6, 6)
for k = 1:size(βs,1)
BLAS.syr!('U', ws[k], (βs[k,:]' .- b1)'[:], weightedW)
end
W1 = Symmetric(weightedW / (length(ids) * R))
criter = maximum([maximum(abs(b0 .- b1)./abs(b0)), maximum(abs(W1.-W0)./abs(W0))])
b0 = b1
W0 = W1
end
b0
W0
209.007623 seconds (1.00 G allocations: 139.476 GB, 26.76% gc time) -0.937996 -0.221032 2.43001 1.84637 -8.83472 -8.97277
6×6 Symmetric{Float64,Array{Float64,2}}:
0.283332 -0.0156035 0.983562 0.666749 2.42428 2.28836
-0.0156035 0.152333 0.248331 0.175803 -0.18654 -0.246001
0.983562 0.248331 4.10506 2.55159 8.58359 7.94201
0.666749 0.175803 2.55159 2.30071 5.46891 4.82644
2.42428 -0.18654 8.58359 5.46891 28.2993 22.3985
2.28836 -0.246001 7.94201 4.82644 22.3985 22.5691
My results do not match Train’s precisely, but that is likely due to simulation variation. As you can see, the estimated means are fairly close while the covariances are markedly different, sometimes by a factor of 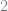
Standard Errors
We can derive the standard errors from the conditional expectation function. Remember that it is approximated by (for each agent)

At the true parameter value 


This is the only term in the conditional expectation that depends on
![\frac{\mathcal{E}_i(\mu,\Sigma\ \vert\ \hat{\mu},\hat{\Sigma})}{d\mu} = \left[\frac{1}{R} \sum_r - w_{nr} \Sigma^{-1}(\beta_{ir} - \mu) \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cmathcal%7BE%7D_i%28%5Cmu%2C%5CSigma%5C+%5Cvert%5C+%5Chat%7B%5Cmu%7D%2C%5Chat%7B%5CSigma%7D%29%7D%7Bd%5Cmu%7D+%3D+%5Cleft%5B%5Cfrac%7B1%7D%7BR%7D+%5Csum_r+-+w_%7Bnr%7D+%5CSigma%5E%7B-1%7D%28%5Cbeta_%7Bir%7D+-+%5Cmu%29+%5Cright%5D+&bg=ffffff&fg=73757D&s=0&c=20201002)
and that
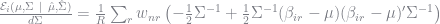
The standard errors are the square-root of the inverse product of the scores. The following code carries out these calculations
# Implementing Mean Scores myObs = -ws .* (inv(W0)*(βs .- b0)')' byGroup = [myObs[200*(i-1)+1:200*i,:] for i in ids] scores = vcat([sum(byGroup[j],1)/200 for j = 1:length(byGroup)]...) # Implementing Covariance Scores Wnew = full(inv(W0)) myObs = [ws[k] .* (-0.5*Wnew + 0.5*Wnew*(βs[k,:] .- b0')*(βs[k,:] .- b0')'*Wnew) for k = 1:size(βs,1)] byGroup = [myObs[200*(i-1)+1:200*i,:] for i in ids] scores2 = vcat([filter(e->e≢ 0.0, UpperTriangular(sum(byGroup[j])/200)[:])' for j = 1:length(byGroup)]...) scores = hcat(scores, scores2) sqrt(diag(inv(scores'scores)))
27-element Array{Float64,1}:
0.0362047
0.026356
0.135586
0.105757
0.340716
0.316128
0.035527
0.0346384
0.0153336
0.261613
0.146027
0.532056
0.188615
⋮
0.289787
0.644983
0.313356
2.4379
1.7378
3.57168
0.596731
0.298847
2.22261
1.58938
5.6801
2.68719
Gaussian Mixture Models
A popular class of models that the EM algorithm has been applied to extensively are Gaussian Mixture Models. This is also the starting point for Arcidiacono & Jones (2003), which is why I am going over it now. The underlying assumption is that the observed sample is generated from a set of 


The likelihood of an observation

i.e. the sum of individual likelihoods multiplied by their probability of being drawn from a given subpopulation (here

This does not have a separable form in the 


where
by

By the properties of the natural logarithm, we can separate the objective function to
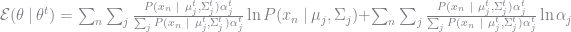
Note that the first sum does not depend on 
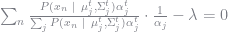
where 

so

A similar process can be carried out on the first sum, although it is easy to see that this term corresponds to our standard weighted maximum likelihood estimator of the normal distribution. To demonstrate this algorithm, I apply it to categorizing the eruptions of Old Faithful (this is one of the examples of EM algorithms used on Wikipedia). The data for this exercise can be found here. Old Faithful has two different modes, a short duration/short delay and a long duration/long delay. We assume that the eruptions in each mode have eruption and delay times that are multivariate normally distributed.
of = readtable("[path]/Old Faithful.csv", header = true, separator = ',');
W0 = [eye(2)*10 eye(2) * 15]
b0 = [5.0 40.0; 6.0 80.0]
α = [0.5 0.5]
We can program our pdf as
function P( x, b, W )
return (1/(2*pi*det(W)^(1/2)))*exp( -0.5*(x - b)'*inv(W)*(x - b) )
end
This is the full calculation
dif = []
for count=1:300
PMat = zeros(size(ofMat))
for k = 1:size(ofMat,1)
obSub = ofMat[k,:]
for j = 1:size(b0, 1)
PMat[k,j] = P(obSub, b0[j,:], W0[:,2*(j-1)+1:2*(j-1)+2])[1]
end
end
denom = PMat * α'
h = PMat .* α ./ denom
α1 = sum(h, 1)/size(PMat,1)
b1 = similar(b0)
W1 = similar(W0)
for j=1:2
b1[j,:] = sum(ofMat .* h[:,j],1)./sum(h[:,j])
dif = (ofMat .- b0[j,:]')
W1[:,2*(j-1)+1:2*(j-1)+2] = sum([h[k,j]*dif[k,:]*dif[k,:]' for k = 1:size(dif,1)])./sum(h[:,j])
end
α = α1
b0 = b1
W0 = W1
end
b0
0.865346 seconds (7.16 M allocations: 644.701 MB, 10.39% gc time)
2×2 Array{Float64,2}:
2.03639 54.4785
4.28966 79.9681
α
1×2 Array{Float64,2}:
0.355873 0.644127
W0
2×4 Array{Float64,2}:
0.0691677 0.435168 0.169968 0.940609
0.435168 33.6973 0.940609 36.0462
Note that there was no need to program analytic gradients or to use an optimization routine. Coding this example took me roughly ten minutes. While the algorithm might be slower than standard maximum likelihood it won’t always be, and you make up significant time by avoiding complex coding. This is one of the strengths of the EM algorithm.
