It is difficult (if not impossible) to derive analytic solutions to many problems in economics. Economists must therefore rely on numerical methods to derive approximate solutions to these problems. For instance, consider solving the standard growth model in macroeconomics

We could solve this problem in many ways. One way would be to write the problem as a dynamic program and use approximate value function iteration. The researcher first discretizes the state space and then solves the for the value function at each point and interpolates for the value function in between points. This can be computationally expensive however and will not provide an analytic approximation. If we were interested in getting an analytic approximation instead, we could use the Homotopy Analysis Method proposed by Liao Shijun. While there is no guarantee that this method will be any less complex, it is definitely an interesting methodology and helped me experiment with Julia’s implementation of a Computer Algebra System (CAS).
Basic Mechanics
In the Homotopy Analysis Method, we create a homotopy between a solution that is easy to solve and the solution we are interested in. The homotopy will depend on a parameter 



We are interested in policy functions for 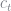






We then look for solutions to 
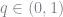


This assumption seems strong at first, but with a few adjustments can be made more reasonable. For the time being just note that 

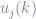


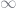

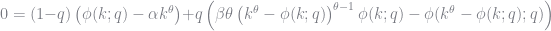
This looks very complex, but setting 
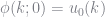


Technically, you can proceed as above and write out the higher order terms. It will be a pain and you will make mistakes. Better to have a computer do it for you. Before we start doing this with Julia, I want to write out the generalized formulation of the Homotopy Analysis Method. Let 



![H(q) = (1-q)\mathcal{L}\left[\phi(k;q) - u_0(k) \right] + q h H(k) R(k;q)](https://s0.wp.com/latex.php?latex=H%28q%29+%3D+%281-q%29%5Cmathcal%7BL%7D%5Cleft%5B%5Cphi%28k%3Bq%29+-+u_0%28k%29+%5Cright%5D+%2B+q+h+H%28k%29+R%28k%3Bq%29+&bg=ffffff&fg=73757D&s=0&c=20201002)
Adding in these additional pieces will not change the solution to our initial guess or the solution to our first order conditions. However, they offer flexibility that will help us ensure that our approximation will converge or improve the rate of convergence. In fact, we call
SymEngine / SymPy
The Homotopy Analysis Method relies on the researchers ability to take high order derivatives of potentially complex expressions. Doing this by hand is unfeasible, even for relatively simple problem like the baby growth model. Computer Algebra Systems can take care of the accounting for us, making this method simple, fast, and reliable. If you want a really powerful CAS, go learn Mathematica. I am more interested in exploring what Julia has to offer, so I tried SymEngine and Sympy. SymEngine is very fast while SymPy is more flexible, so which one you use really depends on your needs. I will give a brief overview of both methods.
Download both packages in the usual way. SymPy requires that you have Python installed and the Python package Sympy. It then uses PyCall to make SymPy available in Julia. For more information on installation, you can view their documentation here. SymEngine is just a wrapper for that C+ library and can simply be downloaded using Pkg.add.
using SymEngine using Base.Cartesian
SymEngine will treat symbols as variables and performs basic operations on them. Suppose we want to define the production function in baby growth model. First, we declare our variable 

k = symbols(:k) θ = 0.33 y = k^θ
k^0.33
We can perform any algebraic manipulations we want to the symbol
diff(y, k)
0.33*k^(-0.67)
We can even leave parameters undefined and perform these operations. For instance, rather than defining
k = symbols(:k) θ = symbols(:θ) y = k^θ diff(y,k)
k^(-1 + θ)*θ
When we want to evaluate
subs(y, subs(y, θ => 0.33))
k^0.33
We ultimately will want to evaluate these expressions as floats. However, if you substitute for both parameters above you will find an odd result.
val = subs(subs(y, θ => 0.33), k => 2.0)
1.25701337452183
typeof(val)
SymEngine.Basic
We get around this by using the function N(). This takes the SymEngine.Basic type and returns a Float64 when it can.
typeof(N(val))
Float64
Also, we can use the following shorthand for subs
subs(y, θ => 0.33) == y(θ => 0.33)
The syntax for SymPy is similar, but there more nuances that you need to get used to. First, to load SymPy you need to include the module with a macro
using PyCall @pyimport sympy
To declare a symbol, we use SymPy’s symbol function, which will return a PyCall.PyObject
q = sympy.Symbol("q")
x_0 = sympy.Symbol("x_0")
ϕ = x_0
@time @nexprs 10 j->(ϕ += x_j *q^j)
PyObject q**10*x_10 + q**9*x_9 + q**8*x_8 + q**7*x_7 + q**6*x_6 + q**5*x_5 + q**4*x_4 + q**3*x_3 + q**2*x_2 + q*x_1 + x_0
We can manipulate this object in the same way that we manipulated the SymEngine.Basic object. We can differentiate using sympy.diff. We can multiply by a constant or add two objects together. However, you should note that in the basic implementation of SymPy you cannot pre-multiply by a constant, only post-multiply. So if 
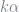
Substituting in values is accomplished by the following
y[:subs](k, 1.0)
PyObject 0.798317932252050
We can convert this to a float simply by piping, i.e.
y[:subs](k, 1.0) |> float
0.798317932252050
My preference for using SymPy comes from the fact that it can carry out pretty robust simplification. The derivatives we are dealing with are complex (lots of powers nested inside powers) but we will often be able to choose initial guesses and auxiliary functions to reduce the number of derivatives we need to cancel. In order to do this however, the CAS needs to be able to simplify an expression. SymEngine does not appear to do this yet, but SymPy does. If you want to use SymPy (and it is what I will be using) be sure to check out its rules for simplification. It will not perform simplifications unless they apply generally. You can read more about this here. This is enough to get us started, so back to the baby growth model.
Baby Growth Model
The first thing we need to do is parameterize the problem. 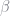

β = 0.8 θ = 0.33 α = 0.6 h = -1.0
We need a quick way to create polynomials of an arbitrary degree. I like to use the Base.Cartesian package. With the macro @nexprs we can create multiple variables with the same prefix in one line of code. For instance,
q = symbols(:q) @nexprs 5 j->(x_j = symbols(:x_j)) x_0 = symbols(:x_0) ϕ = x_0 @nexprs 5 j->(ϕ += x_j *q^j)
x_0 + q*x_1 + q^2*x_2 + q^3*x_3 + q^4*x_4 + q^5*x_5
Everything here is a symbol except for the exponents. Ultimately, each of the 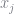
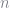
ϕ(q=>1)
x_0 + x_1 + x_2 + x_3 + x_4 + x_5
Our goal is to figure out what the functions 

![D_n\left[\cdot \right] = \frac{1}{(n-1)!}\frac{\partial^n}{\partial q^n}](https://s0.wp.com/latex.php?latex=D_n%5Cleft%5B%5Ccdot+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7B%28n-1%29%21%7D%5Cfrac%7B%5Cpartial%5En%7D%7B%5Cpartial+q%5En%7D+&bg=ffffff&fg=73757D&s=0&c=20201002)
To see why this is useful, it helps to calculate the first few coefficients 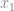

Remember that 

or 

![\frac{\partial H(q)}{\partial q} = \phi(q)^{\prime\prime} - \phi(q)^{\prime} - \left[q \phi(q)^{\prime\prime} + \phi(q)^{\prime}\right] + q \left[ R_n^{\prime}\phi(q)^{\prime\prime} + R_n^{\prime\prime}\phi(q)^{\prime 2} \right] + 2 R_n^{\prime}\phi(q)^{\prime}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+H%28q%29%7D%7B%5Cpartial+q%7D+%3D+%5Cphi%28q%29%5E%7B%5Cprime%5Cprime%7D+-+%5Cphi%28q%29%5E%7B%5Cprime%7D+-+%5Cleft%5Bq+%5Cphi%28q%29%5E%7B%5Cprime%5Cprime%7D+%2B+%5Cphi%28q%29%5E%7B%5Cprime%7D%5Cright%5D+%2B+q+%5Cleft%5B+R_n%5E%7B%5Cprime%7D%5Cphi%28q%29%5E%7B%5Cprime%5Cprime%7D+%2B+R_n%5E%7B%5Cprime%5Cprime%7D%5Cphi%28q%29%5E%7B%5Cprime+2%7D+%5Cright%5D+%2B+2+R_n%5E%7B%5Cprime%7D%5Cphi%28q%29%5E%7B%5Cprime%7D++&bg=ffffff&fg=73757D&s=0&c=20201002)
Again, evaluating at
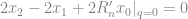
or

If you carried this out for higher order derivatives you would notice that for 
![x_n = x_{n-1} - D_n\left[R_n\right] \vert_{q=0}](https://s0.wp.com/latex.php?latex=x_n+%3D+x_%7Bn-1%7D+-++D_n%5Cleft%5BR_n%5Cright%5D+%5Cvert_%7Bq%3D0%7D+&bg=ffffff&fg=73757D&s=0&c=20201002)
Programming the Homotopy Analysis Method
function F′(express::SymEngine.Basic, n)
for i = 1:n
express = diff(express, q)
end
express
end
function x_n(n, x0, c0, Hk)
@eval begin
q = sympy.Symbol("q", positive = true)
ϕ = sympy.Symbol("x_0")
# Generate Polynomial
@nexprs $n j->(x_j = sympy.Symbol("x_j"))
@nexprs $n j->(ϕ += x_j * q^j)
ϕ = ϕ[:subs](x_0, $x0)
R_n = (k^θ + k*(1-δ) - ϕ)^(θ-1)*ϕ*β*θ - ϕ[:subs](k, k^θ + k*(1-δ) - ϕ)
x__0 = q*0
@nexprs $n j->( begin
x__j = sympy.simplify(x__{j-1} + $Hk*$c0*F′(R_n, j-1)[:subs](q, 0)/factorial(j-1))
ϕ = ϕ[:subs](x_j, x__j)
R_n = (k^θ + k*(1-δ) - ϕ)^(θ-1)*ϕ*β*θ - ϕ[:subs](k, k^θ + k*(1-δ) - ϕ)
end)
start = $x0
@nexprs $n j->(start += x__j )
sympy.simplify(start)
end
end
This is a special case where we know the exact solution to our problem. The solution to the baby growth model is 
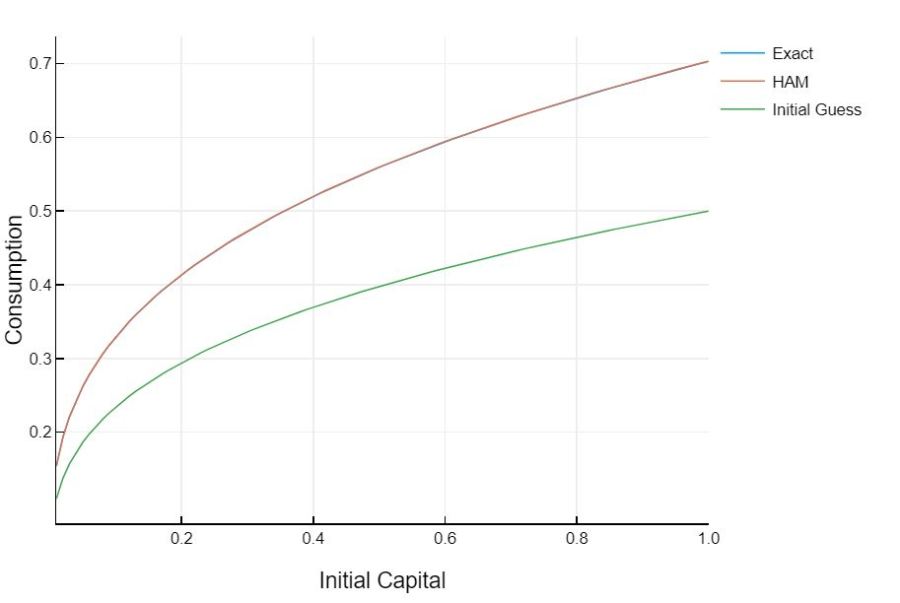
Adding Depreciation
The baby growth model seemed a bit contrived. We already knew the functional form of the solution and so could make a good initial guess. If we add in depreciation however, we don’t have that same luxury. With depreciation, the optimal consumption rule will not be to consume a constant share of output. But that is okay. It will not materially impact our analysis or the good
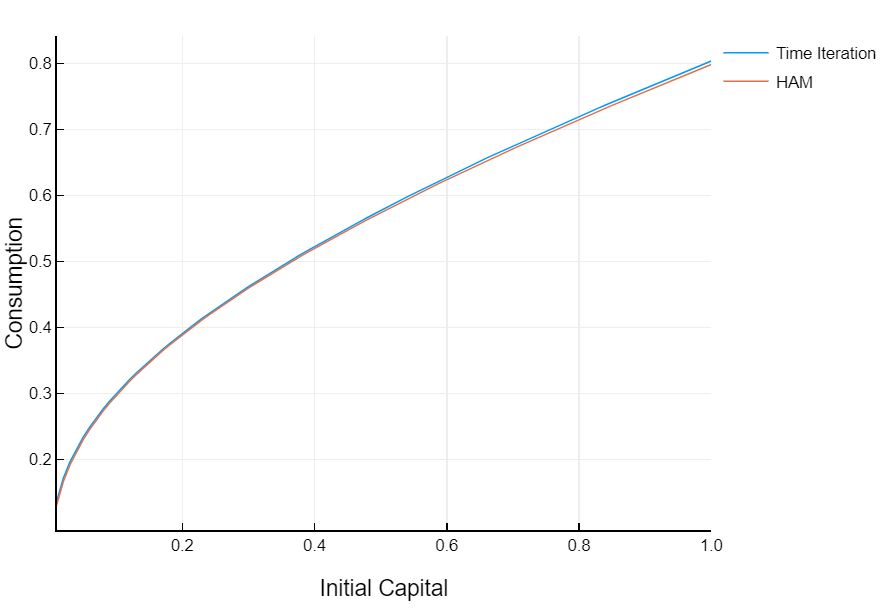
It appears that this approximation is worse than the no depreciation case, but it is actually the time iteration curve that is incorrect. My time iteration code is only set up to solve a model with a non-inelastic supply of labor. Instead of solving a model with utility
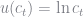
I’m actually solving a model with utility

with 
One point that we haven’t discussed in depth is how to choose the convergence control parameter. Our approximations were very accurate but depended heavily on this constant. In the full-depreciation example the convergence control parameter was set to 

- Ignore
- Choose an initial guess that conforms with the boundary conditions of your problem (not heuristic, this is just necessary) and, if possible, lead to separable terms in the nonlinear equation
- Choose
- Choose
For 


Notice how much simpler this term is than if we guessed 

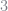

we just remove a term from 

